Geralmente, quando se fala em aprendizado de máquina para mobile, é mais comum ver códigos escritos em Python ou R, rodando do lado do servidor. No entanto, há casos em que compensa mais fazer o processamento localmente (por poder ser feito offline, e não sobrecarregar o server). Por isso o uso de Swift é justificável. Uns 4 anos atrás, eu falaria pra usar o OpenCV rodando nativo em C++, mas os tempos são outros.
Se você, caro leitor, nunca teve contato com inteligência artificial, não tema; este artigo não assume que você conheça previamente nada sobre.
-
Resumo
Vamos juntos, neste artigo, estudar a base de dados sobre Recursos Humanos do Kaggle, e criar uma nova implementação do algoritmo Random Forest na linguagem Swift. Em termos da linguagem Swift, discutiremos generics, ponteiros e paralelização. De Aprendizado de Máquina, vamos falar de engenharia de features, dados, parâmetros e validação. Sobre engenharia de algoritmos, vamos ver complexidade, otimização e estruturas de dados.
-
Introdução
Em termos de frameworks para ML (machine learning), o Swift não está muito bem. Existem alguns projetos isolados, mas todos são promessas inacabadas, e nenhum tinha o algoritmo que eu queria usar (Random Forest). Logo, como eu não queria incentivar o black-box que já rola na área, surgiu este artigo: escrever o algoritmo. Eu não tenho como ressaltar isso o suficiente:
E S C R E V A S E U S A L G O R I T M O S
Pra quem quer se aprofundar na área, recomento o livro clássico Inteligência Artificial: uma abordagem moderna e o curso de Stanford (os dois rolavam soltos em pendrives quando eu cursei essa disciplina na universidade).
Neste artigo, vamos falar sobre Recursos Humanos, e como identificar funcionários que vão pedir demissão.
-
Sobre homens e dados
Primeiramente, vamos falar dos nossos dados. A base de recursos humanos é atualmente (Fev. 2017) a terceira mais votada no Kaggle. Ela tem um sutil disclaimer:
This dataset is simulated. Logo, qualquer informação que tirarmos daqui não deve ser levada muito a sério.Antes de qualquer coisa, vamos dar uma limpada na base de dados, uma engenharia de features. Isso geralmente consiste em descartar dados menos relevantes, e realizar operações nos dados restantes.
Um exemplo maravilhoso de engenharia de features está nos dados dos passageiros do Titanic. Ao correlacionar as entradas com a saída, o fator
sobreviveu? Sim ou não, vemos que as três informações claramente mais importantes são [Idade, Sexo, Classe]. Mulhers com mais de trinta anos, meninos com menos de dez anos, e passageiros da primeira classe, tem muito mais chances de sobreviver. Todavia, olhando cuidadosamente os nomes dos passageiros, podemos extrair o título dele (ex: Mr., Miss., Mrs.) que se torna uma feature poderosíssima.Escrevi um pequeno trecho de código em
Pythonpra fazer esse trabalho por nós:#!/usr/bin/env python import pandas as pd import numpy as np df = pd.read_csv('HR.csv') df = df.drop(df.columns[[0,5,7,8,9]], axis=1)#kill uninteresting rows df.drop_duplicates().to_csv('database.csv', index=False)As colunas
[Satisfação do funcionário, acidentes no trabalho, se foram promovidos recentemente, departamento, salário]contém os dados menos correlacionados com a saída dos funcionários. Isso nos deixa com os seguintes:Variável Correlação com Y Anos na empresa 0.144822 Média de horas por mês 0.071287 Número de projetos realizados 0.023787 Última avaliação do funcionário pela empresa 0.006567 -
‘Florestal Randômico’
O algoritmo Random Forest, ou como eu o apelido carinhosamente, Mata Atlântica, é um classificador supervisionado. Em outras palavras, ele divide dados em classes, e precisa saber previamente a classe dos seus dados para aprender a classificar outros. Classe é o tipo do dado, no nosso caso, se o funcionário pediu ou não demissão.
Em termos simples, ele cria múltiplas árvores de decisão, só que cada árvore usa um subconjunto aleatório de features, e depois usamos BAgging para decidir entre as árvores. Uma verdadeira sacada (migué) que performa, pasme, impressionantemente bem e rápido. Na nossa implementação, vamos dar suporte aos seguintes parâmetros:
Nome Tipo Descrição Padrão Profundidade Máxima Int(1,∞)Altura máxima de cada árvore, ou seja, máxima distância entre a raiz e as folhas. Aumentar esse número deixa o algoritmo mais rápido e menos preciso 10Tamanho Mínimo do Nó Int(1,∞)Tamanho mínimo do subconjunto do datasetno qual cada nó é dividido. Aumentar esse número deixa o algoritmo mais rápido e menos preciso50Tamanho de SampleDouble(0,1)Porcentagem do dataseta ser “sampleada” em cada árvore. Ajuda a deixar cada árvore diferente entre si0.1Número de Árvores Int(1,∞)Número de árvores construídas 10Seed StringSemente do gerador de números aleatórios "Seed"Tipo de Split [All, Sqrt, Log2]Número de features usado em cada split. Ajuda a deixar cada árvore diferente entre si SqrtÁrvores diferentes entre si são o charme do
Random Forest. Vamos entender isso logo. Eis o pseudo-código que vamos implementar:randomForest: Seja D o nosso dataset Para cada árvore a ser construída: seja S um subconjunto de D seja A(S) uma raiz de árvore A.M = obterSplit ( A ) split ( A ) obterSplit ( Raiz de árvore A ): seja M o melhor split encontrado até o momento para cada feature F do split: para cada F[N] a feature de cada linha N de A.S: seja D,E subconjuntos de A.S para cada G[N] a feature de cada linha N de A.S: se G[N]>F[N] adicione G[N] a D caso contrário adicione a E se M'(D,E) for um split melhor que M, M recebe M'(D,E) retorna M split ( Nó de árvore A ): Se a direita, ou esqurerda do split de A for vazia, retorne nó folha (A.M) Se chegamos na profundidade máxima da árvore, retorne nó folha (A.M) Se a esquerda do split for menor que o tamanho mínimo: A.Nó_Esquerda = nó folha (A.M.E) Caso contrário: A.Nó_Esquerda = obterSplit(A.M.E) split (A.Nó_Esquerda) Se a direita do split for menor que o tamanho mínimo: A.Nó_Direita = nó folha (A.M.D) Caso contrário: A.Nó_Direita = obterSplit(A.M.D) split (A.Nó_Direita)Qual é a complexidade deste algoritmo? Digamos que
Lé o número de linhas do dataset,Co total de features,Ko número de classes diferentes, eTo total de árvores construídas. Supondo que para determinar se um Split é melhor do que outro, usamos o coeficiente Gini, que tem complexidadeO(L * K), a complexidade do algoritmo seria:Compl. de construir a árvore: N log( N ) Compl. de cada nó: C * L * ( L + L * K ) ≃ C * L² * K Resultado: O(CL²K log( CL²K ))Note que estamos olhando de maneira quadrática pro dataset.
-
Implementação em Swift
5.1 Arrays vs Ponteiros
A estrutura de dados
Array, em Swift é muito conveniente, mas muito lenta. Vamos fazer um benchmark?let bm = BenchmarkTest.init(count: 1000000) bm.begin()Vamos conferir os números de acesso:
Array Access: 0.0430499911308289 s NSMutableArray Access: 0.519761979579926 s Pointer Access: 0.0407860279083252 sE os tempos de alloc/dealloc:
Array Alloc: 0.01119 s NSMutableArray Alloc: 2.32907 s UnsafeMutablePointer Alloc: 0.00043 sClaro que usando ponteiros INSEGUROS, temos que tomar conta da nossa própria memória. Mas o ganho de desempenho deve compensar esse preço. Como usar arrays de ponteiros? Vamos ver:
// Em vez disso let a:Array<Int> = Array(repeating:Int(0), count:10) // faremos isso let b:UnsafeMutablePointer<Int> = UnsafeMutablePointer<Int>.allocate(capacity: 10 * MemoryLayout<Int>.size) // e para mudar o tamanho do array b = realloc(b, 20*MemoryLayout<Int>.size).assumingMemoryBound(to: Int.self) // e depois de usar b.deallocate(capacity: 10 * MemoryLayout<Int>.size) // Para pegar referencias de structs sem copiar valores nativos, em vez disso let a_copy = test // Faremos isso let b_copy = UnsafeRawPointer(Unmanaged.passUnretained(test).toOpaque()) // E para acessar Unmanaged<Int>.fromOpaque(b_copy).takeUnretainedValue()Lembre-se que
reallocé uma operação cara. A implementação deArray, por exemplo, dobra o tamanho quando chegamos no limite. A regra de ouro é sempre que possível fazer umloope calcular o tamanho novo do array, em vez de realocar a cada novo append.5.2 Tipos genéricos
Outro detalhe importante quando trabalhamos com dados é o tipo. Como o Random Forest não é um cara de grandes operações matemáticas, isso não vai importar muito pro nosso caso, e podemos usar
Doublesem dor no peito. De qualquer modo, é muito interessante que implementações de estruturas de dados para Aprendizado de Máquina sejam genéricas. Apanhei um pouco pra deixar tudo genérico, mas considero que o resultado ficou bem interessante. Veja exemplos das declarações:protocol Numeric:Hashable, Comparable class Matrix<T:Numeric> class TreeNode<T:Numeric> protocol ClassifierAlgorithm { associatedtype NumericType:Numeric } class RandomForest<T:Numeric>: ClassifierAlgorithm { typealias NumericType = T } class CrossValidation<T:Numeric, U:ClassifierAlgorithm>: NSObject where U.NumericType == T5.3 Operações paralelas com
OperationNo nosso algoritmo, nada impede que as árvores sejam construídas paralelamente. Em termos de performance, com testes rasos usando
Operation, o tempo de construir nove árvores de três em três é um terço de construir de uma em uma. Pois, vamos ao que interessa, começamos com um gerenciador de operários, também conhecido como sindicato 😂:class PendingOperations { var queueName:String var concurrentOperations:Int init (queueName:String, concurrentOperations:Int) { self.queueName = queueName self.concurrentOperations = concurrentOperations } lazy var buildsInProgress = [NSIndexPath:Operation]() lazy var buildQueue:OperationQueue = { var queue = OperationQueue() queue.name = self.queueName queue.maxConcurrentOperationCount = self.concurrentOperations return queue }() }Uma classe operária oprimida pelo sistema:
class TreeBuilder:Operation { override func main() { ... } }E para convocar uma greve:
for _ in 0..<self.treesCount { let treeBuilder = TreeBuilder.init() treeBuilder.completionBlock = {...} self.pendingOperations.buildQueue.addOperation(treeBuilder) } -
Validação Cruzada e Overfitting
Como validar o nosso modelo na prática? É comum ver em artigos da área frases como
to evaluate our accuracy we used 10-fold cross-validation [...]. Vamos explicar:Acurácia é uma métrica comum para algoritmos de ML, basicamente, previsões corretas/número de testes. Entenda:
private func accuracy(actual:Array<T>, predicted:Array<T>) -> Double { let correct = zip(actual, predicted).reduce(0){ (a: Int, element) in var accumulator = a if element.0 == element.1 { accumulator += 1 } return accumulator } return Double(correct)/Double(actual.count) }Overfitting é o fenômeno que ocorre quando um modelo performa muito bem para para os dados de treino, e muito mal para os dados de teste. Veja um exemplo na seguinte imagem:
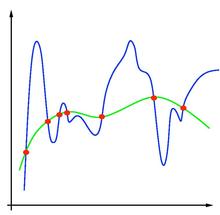
A linha verde é a função que gerou os dados. A linha azul é uma função criada por uma regressão. Dado um novo ponto da linha verde, será que o modelo azul vai predizer corretamente? Não.
A criptonita do overfitting é ter muitos dados. Quanto mais dados, melhor. Sempre.
Validação Cruzada (K-fold Cross Validation) é o conceito de dividir aleatoriamente o dataset em K subconjuntos de tamanho igual, e para cada subconjunto, usar ele de validação e os demais como teste. Entenda:
let dataset:Array<T> = getDataset(), foldCount = 10 let folds:Array<Array<T>> = crossValidationSplit(dataset: dataset, folds: foldCount) for fold in folds { let trainData = datasetByRemovingFold(fold) let testData = fold algorithm.runClassifier(trainData,testData) }Validação cruzada ajuda também a reduzir um fantasma chamado overfitting.
Vamos avaliar nosso algoritmo? Usando os parâmetros padrão, com 10 folds, temos:
Fold 0 had accuracy 0.887876025524157 Fold 1 had accuracy 0.906107566089335 Fold 2 had accuracy 0.880583409298086 Fold 3 had accuracy 0.86873290793072 Fold 4 had accuracy 0.886052871467639 Fold 5 had accuracy 0.896991795806746 Fold 6 had accuracy 0.886052871467639 Fold 7 had accuracy 0.864175022789426 Fold 8 had accuracy 0.877848678213309 Fold 9 had accuracy 0.88514129443938A acurácia média é
0,883. Ou seja, estamos predizento,em média, corretamente se 88% dos funcionários se demitiram ou não. Interessante né? Vamos olhar uma árvore construída: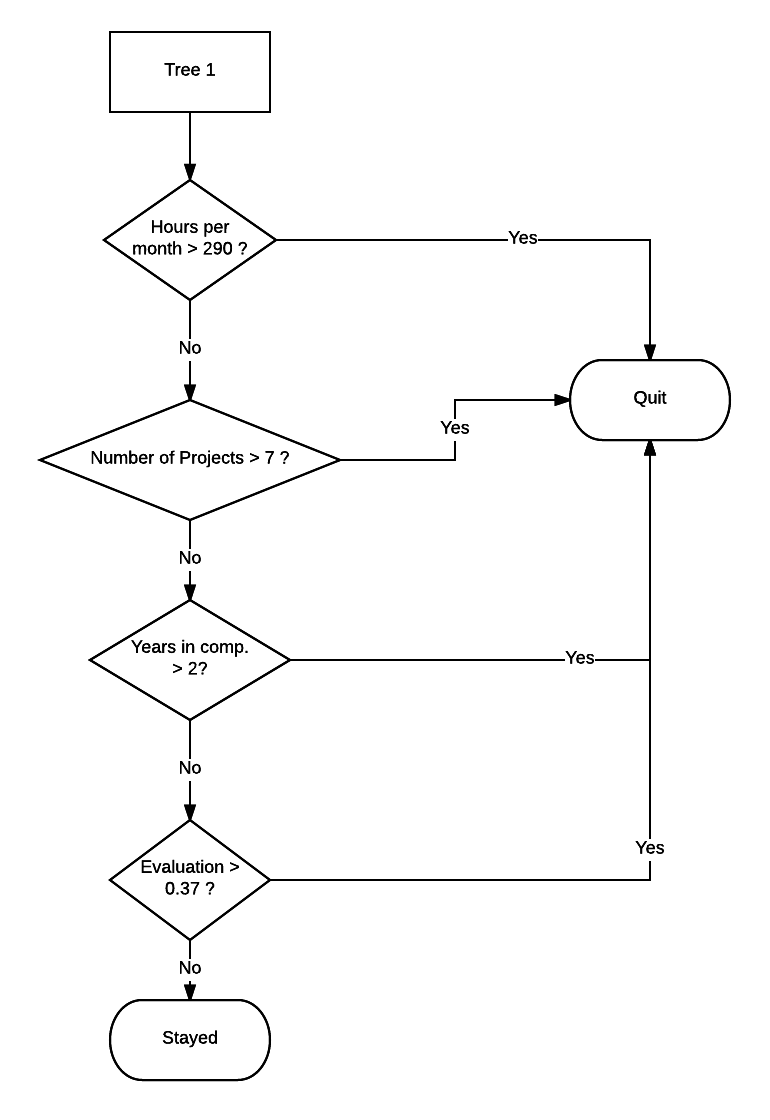
Vamos olhar mais de perto nossa classificação:
Não se demitiu Demitiu Achamos que não se demitiu 85% 12% Achamos que se demitiu 0% 3% Opa. Parece que nosso classificador tem um viés. Isso está acontecendo porque o dataset é muito desbalanceado, ou seja, apenas 15% dos dados são de funcionários que pediram demissão. Vamos mudar nosso sampling para usar mais esta classe (subsampling), ponderar as variáveis na hora de calcular o índice gini e na hora de predizer com o bagging, e mudar nossa métrica pra um indicador que lide melhor com os dados desbalanceados (kappa), como sugerido no famoso artigo 666 de Berkeley:
For each iteration in random forest, draw a bootstrap sample from the minority class. Randomly draw the same number of cases, with replacement, from the majority class […] Since the RF classifier tends to be biased towards the majority class, we shall place a heavier penalty on misclassifying the minority class. We assign a weight to each class, with the minority class given larger weight
-
Conclusão
Nessa nossa breve jornada juntos, implementamos um classificador altamente prático, com um desempenho aceitável. Entendemos como lidar com dados, e a avaliar nossos modelos. Vimos como usar ponteiros, generics, e paralelizar operações em Swift 3. Descobrimos o possível perfil de quem pede demissão. Aprendemos como examinar o resultado do classificador. Obrigado pela leitura. Até a próxima! O código deste artigo pode ser encontrado neste repositório.
Lucas Farris começou com programação em 2006, entrou no mercado mobile em 2011, em 2014 se formou em Ciência da Computação na Unicamp. Atualmente trabalha na Polônia, onde cuida de uma planta robo chamada Саша.